
Fundamentals for Designing Recommendation Systems
Classification
Rooted in statistical learning theory, classification aims to predict the class or category of a sample based on observed features or variables. In other words, given a set of labeled data, the goal of classification is to train a model that can accurately predict the class or category of new, unlabeled data points.
The quality of classification models largely depends on the completeness and relevance of the features used for training. Complete features are those that capture all relevant information about the sample, while irrelevant or redundant features can reduce the accuracy and interpretability of the model.
Recommendation
The main idea behind recommendation systems is to suggest products or information that are relevant and attractive to users based on their preferences and behaviors. In other words, the goal of recommendation is to help users discover items that they might like but may not have been aware of otherwise.
To achieve this goal, recommendation algorithms use a variety of techniques, such as collaborative filtering, content-based filtering, and hybrid methods. Collaborative filtering is based on the idea that users who share similar preferences in the past are likely to have similar preferences in the future. Content-based filtering, on the other hand, focuses on the attributes or features of the items themselves, and recommends items that are similar to those that the user has liked before. Hybrid methods combine these two approaches to leverage their respective strengths and mitigate their weaknesses.
Recommendation algorithms can be classified into two main categories based on the type of data they use: those based on interaction data and those based on sequence data. Interaction data refers to data that captures the interactions or feedback between users and items, such as ratings, clicks, and purchases. Sequence data, on the other hand, captures the order or context in which users interact with items, such as browsing history or search queries.
Collaborative Filtering
Collaborative filtering is based on the idea that users who share similar preferences in the past are likely to have similar preferences in the future. In other words, if two users have rated or interacted with similar items in the past, there is a high chance that they will like similar items in the future.
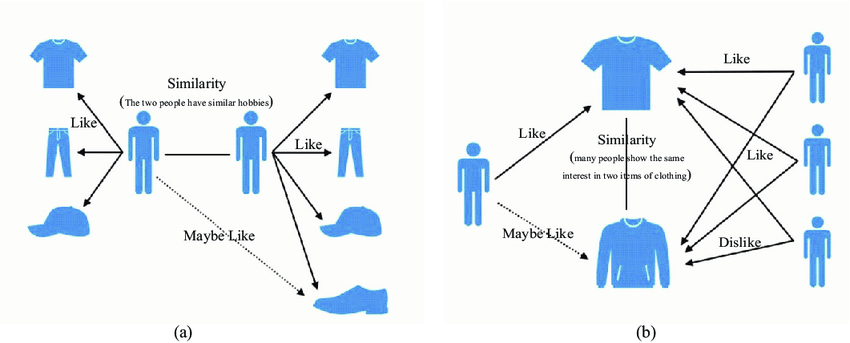
Collaborative filtering can be done in two ways: user-based and item-based. User-based collaborative filtering recommends items to a user based on the preferences of other users who are similar to them. For example, if User A likes movies X, Y, and Z, and User B likes movies X and Y, then User B may be recommended movie Z. Item-based collaborative filtering, on the other hand, recommends items that are similar to the ones that the user has liked before. For example, if User A likes movie X, then they may be recommended movies Y and Z, which are similar to movie X in terms of genre, cast, or plot.
NeuralCF (Neural Collaborative Filtering)
NeuralCF is a state-of-the-art approach that combines neural networks with collaborative filtering techniques to improve the accuracy and performance of recommendations. It is based on the idea that deep neural networks can learn rich and complex representations of user-item interactions and capture nonlinear patterns and dependencies that traditional collaborative filtering methods may miss. In particular, NeuralCF uses a neural network architecture that combines two components: a user embedding layer and an item embedding layer. These layers map each user and item to a low-dimensional vector representation, which encodes their respective features and characteristics.
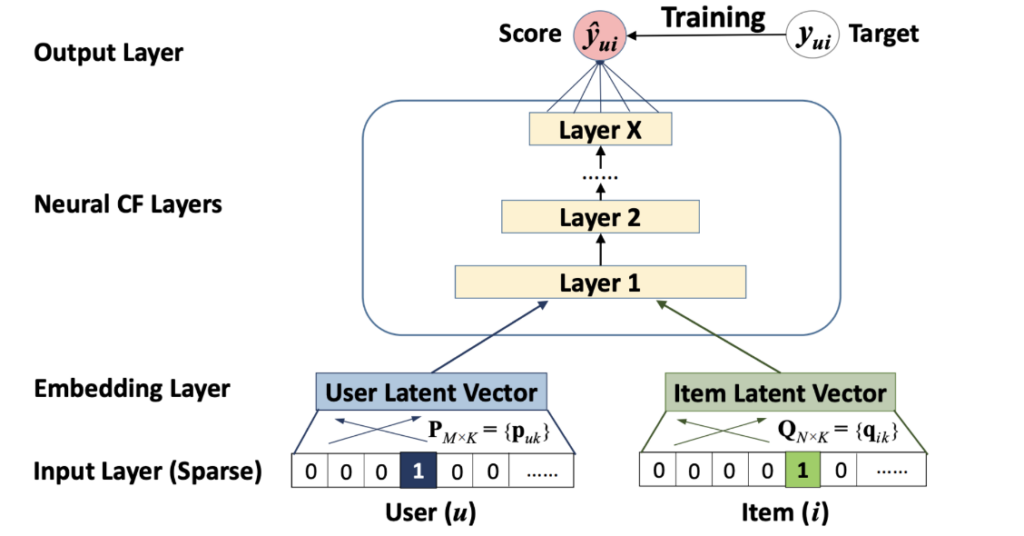
The user and item embeddings are then concatenated and fed into a multilayer perceptron (MLP) that learns to predict the user’s preference or rating for the item. The MLP consists of multiple layers of fully connected neurons that perform nonlinear transformations and feature extraction. The output of the MLP is a scalar value that represents the predicted rating or preference score of the user for the item.
NeuralCF has been shown to outperform several baseline methods in several benchmark datasets and real-world recommendation scenarios. However, it also has some limitations, such as its high computational cost and the potential for overfitting in small or noisy datasets.
DeepFM (Deep Factorization Machine)
DeepFM combines factorization machines with deep neural networks to capture both linear and nonlinear relationships between user and item features in recommendation systems.
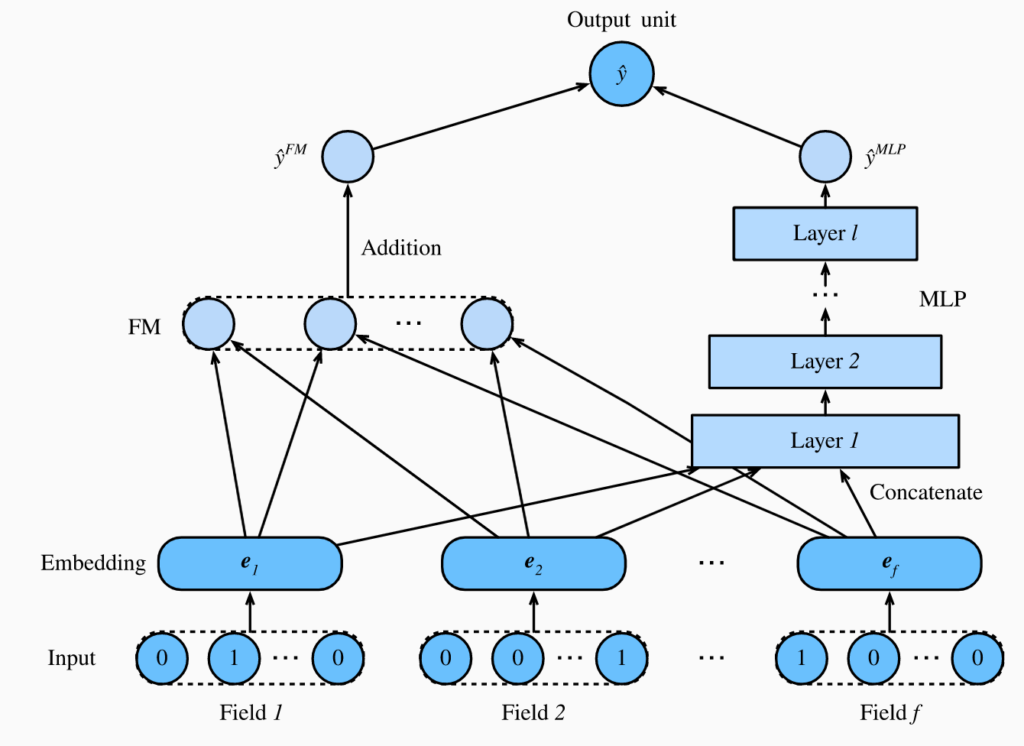
Factorization machines can only capture pairwise interactions between features, whereas DeepFM uses a neural network to learn high-level representations of user and item features, enabling it to capture complex nonlinear interactions.
The model consists of two components: a factorization machine for linear relationships and a neural network for nonlinear relationships. The output of both components is combined to generate the final prediction for user-item interactions.
DeepFM can handle high-dimensional and sparse data and incorporate additional features and contextual information into the recommendation process. It outperforms several state-of-the-art recommendation models, but has limitations such as high computational cost and requiring large training data.
Variations and extensions of DeepFM, such as Wide & Deep and AutoInt, have been proposed to address these challenges and further improve the efficiency of recommendation systems.
DIN (Deep Interest Network)
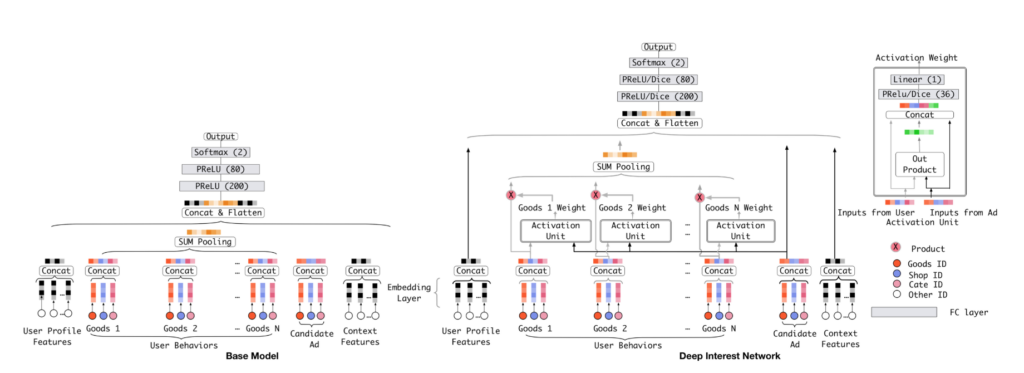
DIN is a neural network-based approach for recommendation systems. It models users’ historical interactions with items and current context to capture their dynamic and diverse interests and preferences. It uses an attention-based neural network to generate a personalized interest vector for each item. The model has four components: a user behavior sequence encoder, an interest extractor, a candidate item selector, and an output layer. DIN outperforms traditional recommendation models by handling high-dimensional and sparse data and incorporating contextual information.
Despite its advantages, DIN has some limitations, such as high computational cost and the need for large amounts of training data. Variations and extensions of DIN, such as DIEN and DSIN, have been proposed to further improve recommendation systems’ performance and efficiency.
Enriching Object Features with Graphs
Before directly using GNN, the characteristics of nodes in the graph topology can be extracted through graph statistics and mining techniques. By combining with traditional machine learning, the node representations can be enriched.
Applications of GNN Algorithms in Recommendation Systems
GNNs are a Natural Fit for Recommendation Systems
Recommendation systems deal with data that naturally has a graph structure, such as user-item interaction data or social network data. GNNs are designed to model and learn from such data and have shown promising results in recommendation tasks, as they can effectively capture the complex relationships and dependencies between users, items, and other contextual factors.
By aggregating the features of neighboring nodes, GNNs can capture the local structure of the graph, while also taking into account the global context of the graph. Moreover, the degree of influence that a node receives from its neighbors depends on their distance in the graph, allowing for a more fine-grained and nuanced representation of the node’s features. This can help GNN-based recommendation models better capture the user’s preferences and make more accurate recommendations.
In the context of interaction data, GNN explicitly encodes collaborative signals by aggregating nodes to enhance the representation learning of users and items. Compared to other models, GNN is more flexible and convenient for modeling multi-hop information.
For sequence data scenarios, converting sequence data to sequence graphs enables more flexible raw transformation of item selection. Additionally, GNN can capture complex user preferences hidden in sequential behaviors through the structure of loops.
NGCF (Neural Graph Collaborative Filtering)
NGCF uses GNN to compute separate user and item feature representations. The GNN layer vector representations are concatenated and a non-linear activation is performed at the output layer. The model is corrected using BCELoss based on reference labeled click data to compute user and item vectors, which is used for CTR related businesses. The model can be trained using CELoss to recommend items. Possible optimizations include message aggregation and activation function selection, as well as loss function selection.
KGCN (Knowledge Graph Convolutional Network)
KGCN is used to address the issues of data sparsity and cold-start in recommendation systems. It leverages the richer semantic information provided by knowledge graphs and designs algorithms to utilize them. The basic idea is to predict whether a user has potential interest in an item that they have not previously interacted with, given the user-item interaction matrix and knowledge graph.
More Algorithms
General recommendation (based on static relational data):
- LightGCN
- GCMC
LightGCN and GCMC are graph-based recommendation algorithms that utilize the static relationship data between users and items to make recommendations. LightGCN is a simpler model that focuses on learning low-dimensional embeddings of users and items using graph convolutional networks. GCMC, on the other hand, is a more complex model that takes into account higher-order interactions between users and items using graph attention networks.
Sequential recommendation (based on temporal data):
- SRGNN
SRGNN is a sequence-based recommendation algorithm that uses the temporal order of user-item interactions to make recommendations. It models the user-item interactions as a sequence graph and learns the user and item embeddings using a gated recurrent unit (GRU) network.
Knowledge graph-based recommendation:
- KGAT
- KGIN
- KGNNLS
KGAT, KGIN, and KGNNLS are knowledge graph-based recommendation algorithms that use the semantic information from knowledge graphs to enhance recommendation performance. KGAT uses graph attention networks to integrate the knowledge graph into the recommendation model, while KGIN uses graph isomorphism network to capture the structural similarity between user-item interactions and knowledge graph entities. KGNNLS, on the other hand, uses a non-linear least squares algorithm to jointly optimize the user-item interactions and knowledge graph representations.
Key Issues to Address
- Graph construction
- Model selection
- Algorithm design
- Activation functions
- Loss functions
Other Tasks
Node2Vec
- Construct a product graph based on user behavior, where each product is represented as a node and edges represent relationships between products, such as co-occurrence or similarity.
- Apply Node2Vec algorithm to the graph to obtain vector representations of the product nodes.
- Recommend products to users based on the nearest neighbor principle, where similar products are recommended to users who have shown interest in a given product.
MetaPath
Methods used in Tencent’s research paper:
- To address the problem of data imbalance, they used MetaPath to obtain node attributes.
- To account for the time factor, they added a duration parameter to the loss function.
GCN/GraphSAGE
The most common application of GNN is in the classification scenario, using network topology information to assist in classification tasks and improve efficiency.
In scenarios where user interaction data is lacking, classification can be used for initial profiling clustering, and exploratory marketing. This can help accumulate data information for subsequent personalized promotion.
RGCN (Relational Graph Convolutional Network)
In the context of a heterogeneous graph, the impact of message propagation between nodes of different types, through different types of edges, should have varying degrees of importance for the target node features.
Based on this intuitive understanding, there is a large class of GNN algorithms based on heterogeneous graphs used to calculate node features on the graph.
Graph Platforms
Graph platforms are used to support graph-based intelligent applications. Starting with graph construction, the process involves data partitioning, feature engineering, model training and optimization, model interpretation, real-time inference, and building complete visualization tools and development scaffolding to facilitate the rapid implementation of graph intelligent applications.